Let’s continue our journey across the software quality (SQ) landscape, as we learned it has the power to improve our code, even ourselves. And it is now time to explain where software quality powers come from.
There is no obscure recipe or reserved knowledge to decide when the desired quality is reached. Actually it is quite the opposite – to really work, SQ should have the following powers:
- Shared
- Computed
- Contextualized
Sharing power: Speaking the quality language
We usually learn a new programming language to build and share concepts with our fellow developers, or participate to a community (well, not always, sometimes we just want to have fun 😉).
Value comes from sharing, and SQ is similar: as it is used and communicated by all participants, it is easier to talk about, and is not reserved to a selected group of experts. A common goal has been set.
With communication comes understanding. With this first power, SQ concepts become familiar, we start digging, and ask questions:
- “I know rule compliance is important, but how do I know when it’s good enough?”
- “How can I keep the complexity down? And what is really complex anyway?”
We are one step closer to ask the final question: “What do I need to actually get something concrete, tangible?”
Well, let’s throw in the “M” word: “Metrics” of course. The source of much of SQ powers comes from Metrics: objective data used to answer the questions and reach the common goal.
And this Goal/Question/Metric approach is a top-down concept from last century (less than 30 years ago).
It is interesting in the way it helps define SQ in a programmatic way (so you can code a quality assessment tool, and run it on its own code, in a beautiful recursive move!)
So SQ is assessed in a straightforward, deterministic way once we agree on what to measure (metrics), and how they transform into quantitative results.
Quality, semantic and computations
Put simply, the top-down approach of SQ assessment breaks down the main quality objectives meaning into computations. They are based on the actual data measured from the source code, and the tools used on this code.
Now that we have a clear idea of the way down, let’s travel back to the surface, to the quality objective.
There are many metrics to consider, produced by commit information, static code analyzers, dynamic ones too, unit test frameworks, integration test suites, tools checking rules for good practices, security, industry standards, etc.
We could even add data from requirements, design, enhancement requests, bugs!
Based on these metrics, we can compute other results, producing higher level metrics. For example:
- The “Rule compliance ratio” is the percentage of violated rules relatively to the total number of rules to comply with.
This requires two metrics: counting the failed and tested rules.
- There are many approaches to code complexity, but if we just take a look at Halstead definitions of code properties, we come up with the definition of difficulty as follows:
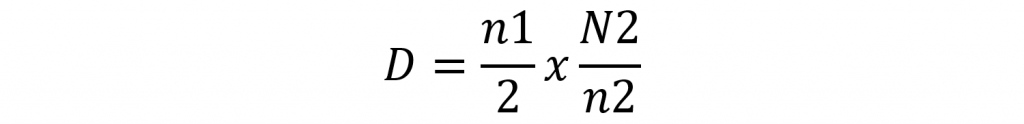
These are simple examples, but the principle is the same for more complex cases: the second power is to aggregate metrics by computation, so we can answer our common goal (the quality objective).
Contextualization: Indicator as a quality translator
So we have a good approach we can agree on and understand well enough so that we can compute it. But one important thing remains: context.
Why is it important? Because it’s much easier to deal with objective data when you know in what context they appear.
- Does 25°C (77°F) make a hot day? It depends where you live, and what month it is.
- Is 0% comment rate a bad thing? Not on a dumb setter function.
- If the compliance ratio is 42%, is it good or bad? It depends if the component is critical, legacy, or freshly coded.
To handle objective metrics and attach them a subjective value, let’s use the indicator concept. And map numerical values to several levels of appreciation, which will bring context to the interpretation.
Indicators can be simply binary (pass/fail on a threshold), or detailed (7 levels of criticality).
The important thing to keep in mind is that they are going to provide meaning you can work with.
And we don’t have to limit ourselves to one indicator per metric. For example the code coverage ratio:
- Can map to a binary indicator to check for a hard threshold
- But also translate to a finer multi-level Indicator, allowing us to better micro-manage.
In essence, the power brought by indicators is to translate numerical metrics into manageable information we are comfortable with.
Gaining software quality powers with objectives, metrics and indicators sounds like a no-brainer.
But is it not too much? Are we not going to spend more time navigating through all of it, and less time having fun coding?
It is a concern, and there is a solution. We’ll cross that bridge next time 😉