Unidentical twins
Code clones can be elusive. First of all, we’re not talking about the dumb copy/paste textual clones, we’re interested in the harder to see algorithmic kind (we met both in a previous post).
And algorithmic clones are the sneaky ones: they disguise using different variable names, muddy the waters with varying number of statements, and hide behind diverging comments.
Déjà-vu
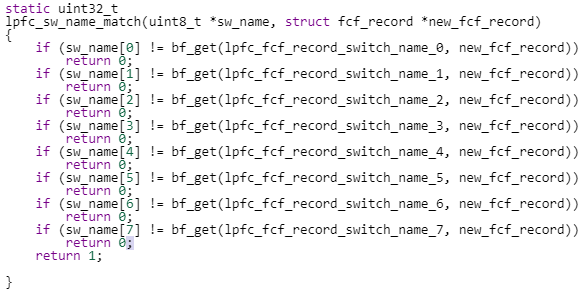
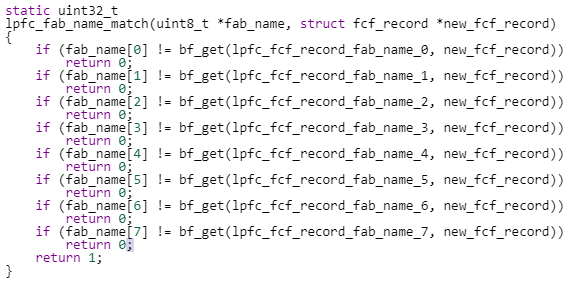
Let’s start with a simple example: here are two functions that are algorithmic clones.
- They have different names
- Out of the two attributes, the first is renamed, the second is the same
- They share the same algorithm, a sequence of eight ‘if’ statements, returning 0 or 1
- Finally, all ‘if’ tests have a lot in common, with a few differences (renamed variables)
 |  |
Have we met before?
Now look at the same first function, next to an attempt at obfuscation.
Unlike the previous example, this is not a case of “clone at first sight”.
And yet they really are the exact same algorithms.
If you are skeptical, keep on reading!
|  |
Algorithmic DNA matching
Using the control flow chart
As discussed in our Anatomy of a source code post, algorithms can be displayed as a chart, showing statements, conditions, control flow change, etc.
Using this representation, all functions from our previous examples have the exact same chart. Yes, even the obfuscated one.
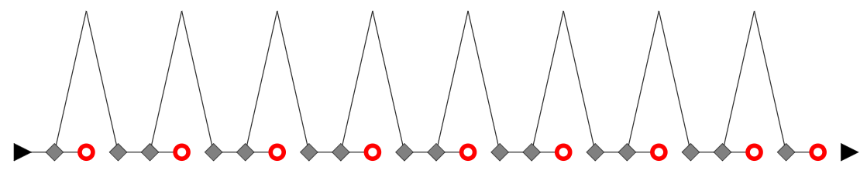
So this method can be used to focus on the very structure of algorithms,.
To do that, we leave out all names, comments and block delimiters. In a way, we are looking at the algorithm’s DNA, and matching it changes clone spotting into a fun graphical game 😊.
Spot the clone!
Here is a first example of real code.
Look at these two functions, and quickly tell if they are algorithmically similar or not.
At first glance, they seem to be the same functions.
But to be sure, you really need to compare each individual line, check variable names and string changes.
This is no fun.
 |  |
Now look at the control flow charts for both functions. It should only take you a few seconds to hit the “Found a Clone” buzzer!
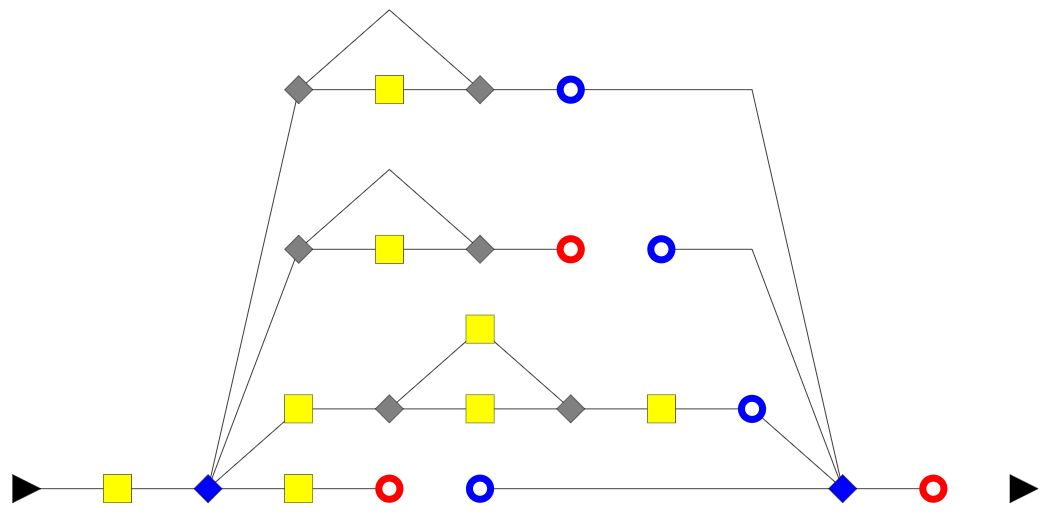 | |
Recognizing algorithms from a long way away
Here is another example.
This function is not that huge (under 300 lines), but if you were asked to look for algorithm similarities, time would suddenly feel very long.
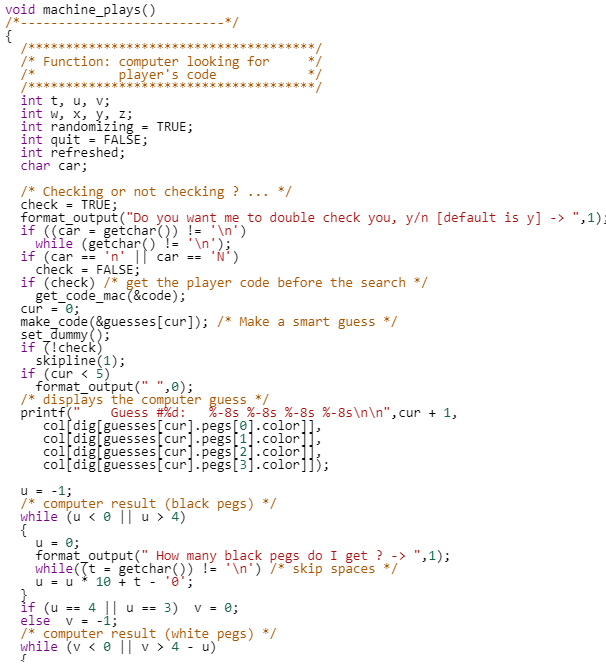 |  |  |  |  |
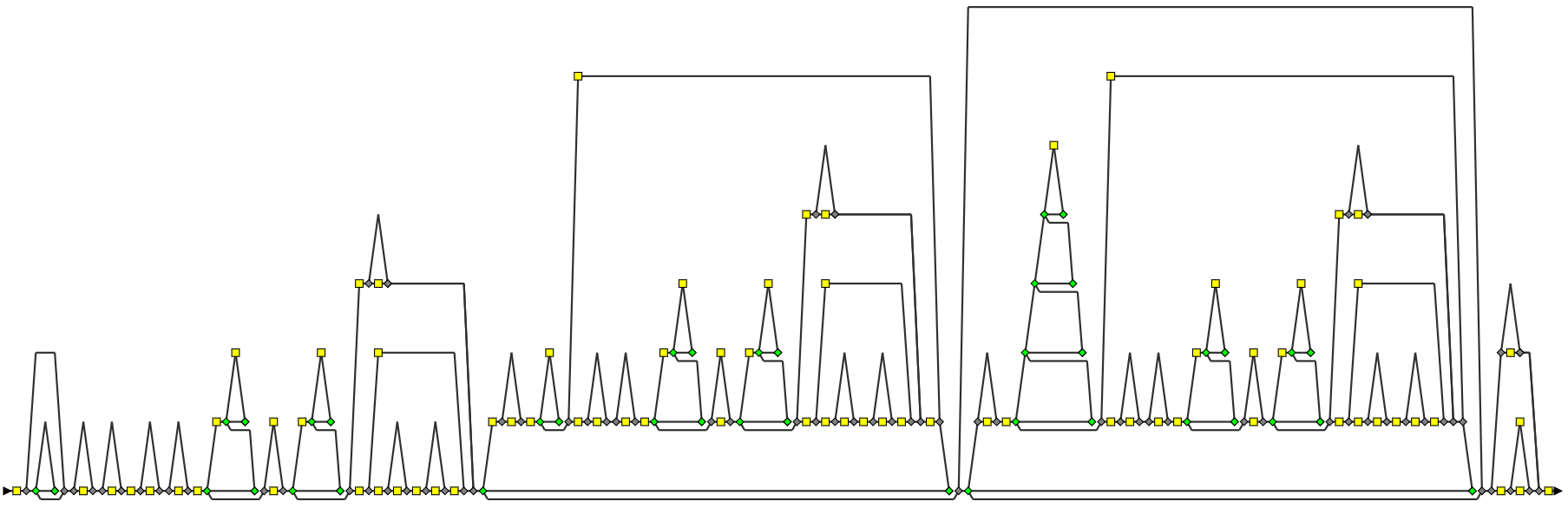
Now look at the corresponding control flow chart. In a few seconds, your eyes will detect similar patterns, and you will just be eager to look into the code and work on these clones!
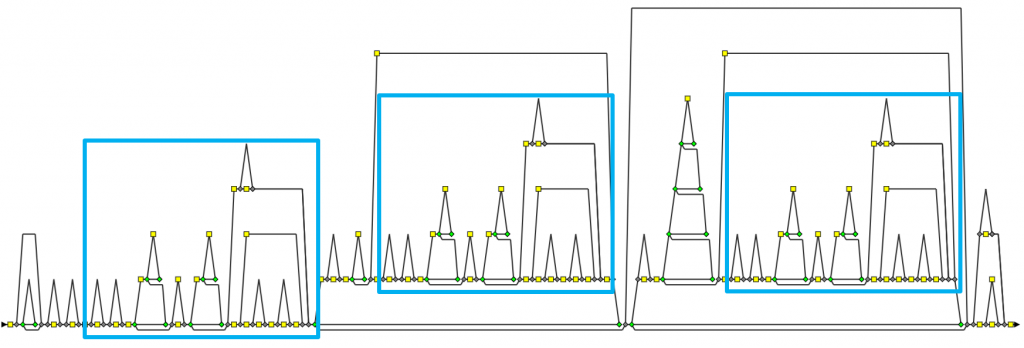
Going further
Now that we know how to look for these clones, the next steps are:
- Search
- Select
- Simplify
First, based on the control flow DNA as an algorithmic signature, we can look for all clones in a project, sorting them from most to less similar (using a threshold to only keep significant clones).
Next, we can select clones which are relevant.
Discarding for example those from legacy code (which may be risky to modify), or from code needing to run on separate targets.
Finally, the selected clones can be simplified (by way of factorization).
Here is the result on our previous example.
 | = | 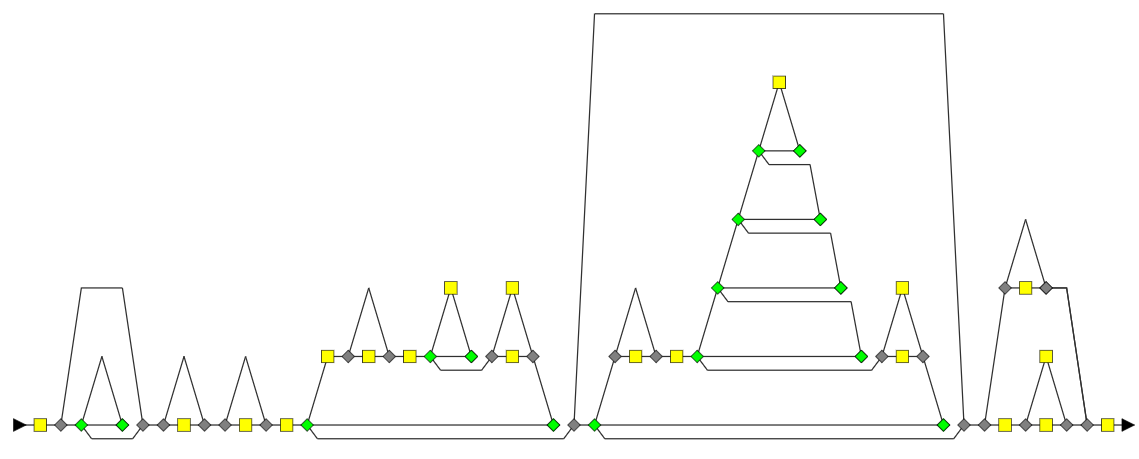 | + | 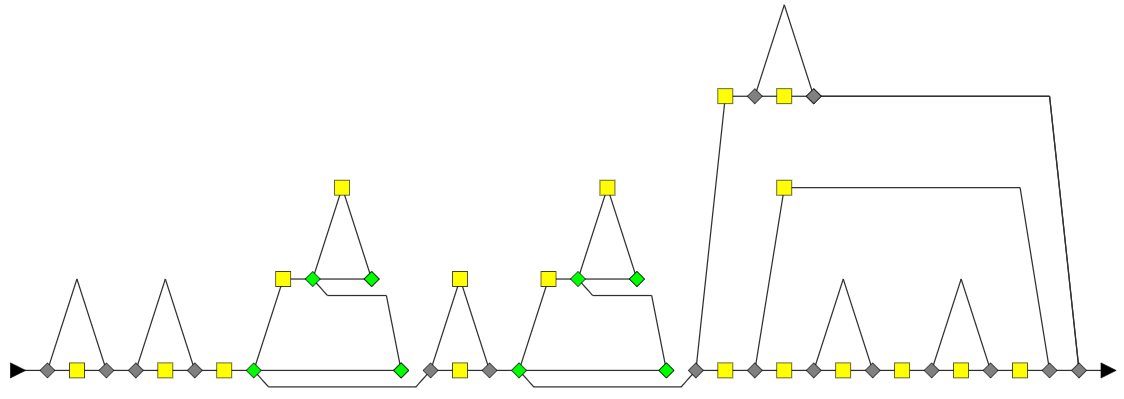 |
The benefits of this factorization are immediate, and durable:
- Smaller footprint
The cloned part (repeated three times) now only appears one time, the resulting two functions are smaller, their complexity is reduced. - Simpler tests
It is easier to test smaller functions., and to ensure test coverage. - Better maintainability
In the future, debug and enhancements won’t suffer from a complex function you’ll have to understand before modifying. - Optimized debug
If a bug is found in the factorized code (which used to be cloned), it will only have to be fixed in one place, and there is no risk of forgetting to fix it everywhere this code was cloned.
Looking ahead
Clone detection leading to factorization is more than an exercise of visual recognition.
We started using terms like complexity, coverage, maintainability, risk. For each one, there are fields of study, standards, methods, best practices, tools.
Software development can greatly benefit from these fields, which assist us in writing better code.
In the next posts, let’s continue exploring the building blocks of a greater edifice.
You guessed it: we’re talking about software quality.