As Software Engineers we are often faced with questions like “Can we deliver the expected software quality?” or “What is the current software quality?”. Can you provide an answer to these questions at any time?
Software quality and how to measure it is the elephant in the room. Everybody knows about it; everybody wants to have “quality”. But nobody talks about it … I assume, that this is why you are reading this article. Because you are interested in software quality and care about it. But first, we have to clarify our understanding of software quality. Are we really using this term with the same meaning and intention?
What is software quality?
In literature, we find many definitions of software quality. The most suitable for our case can be found in ISO 9000 (the “mother of all quality standards”). Therein quality is defined as follows:
“Degree to which a set of inherent characteristics fulfills requirements.” So let us see what we can make out of this. The decomposition of this phrase gives us three parts:
- The first part is the “Degree of fulfillment”. This implies the existence of a target value against which the actual, measured value can be compared.
- The second part is the “set of inherent characteristics”. What we develop is defined by its properties. But not all of them can be used to determine their quality. Inapt for our context are all properties, which can be changed without changing the software, the so-called assigned properties. The quality we want to measure is an inseparable part of our software.
- The third part of the phrase are “requirements”. If we want to measure the degree of fulfillment there is no way around knowing what the requirements are. The definition does not refer to requirements as we as engineers dream to have them (formalized, well-formed, complete, concise, etc.). The term is defined as expectations or needs. These can be the expectations specified in applicable standards like EN 9100, IATF 16949, Automotive SPICE, ISO26262, ISO 21434, etc, and the needs of our stakeholders. And these expectations and needs are our first point of attack.
How to measure software quality?
In the beginning, we can get everything from our stakeholders, but a complete and coherent set of requirements. We get a fuzzy collection of ideas, proposals, questions, and wishes, from which we must derive what we need: formalized requirements. And we do this by performing requirements engineering (RE), starting with the elicitation of the needs of all our stakeholders, and bringing them together. Then we take everything we have gathered and analyze it to determine if we can build a system out of it.
From requirements engineering …
Functionality is one of these expectations, but also less tangible topics like performance, maintainability, reliability, security, etc., the so-called non-functional aspects. During the process of requirements engineering, we try to find out the meaning of these topics for our development by decomposing and turning them into requirements, first on system level, then on the software level. And if we have derived requirements according to common best practice, they should meet criteria like necessary, unambiguous, complete, correct, and especially feasible and verifiable.
… to measuring software quality through indicators
Feasible means that there is at least one way imaginable to realize the requirement. Hence, it is achievable and realistic, meaning we know what to do. And if a requirement is verifiable, this means that criteria have been defined, how to show the correct and complete implementation of the requirement. This is of particular importance for non-functional requirements. For functional requirements, we have a clear statement of what is expected, and can (in most cases) directly derive a verification case containing expected values out of this. For non-functional requirements, which mainly define the inherent characteristics that make up our quality, we must create a relation between what to do to implement the characteristics, what can be measured (the measures), and how this indicates the achievement of quality. As in many cases, the mapping of measures to characteristics is not one-to-one, the measures can be aggregated into indicators.
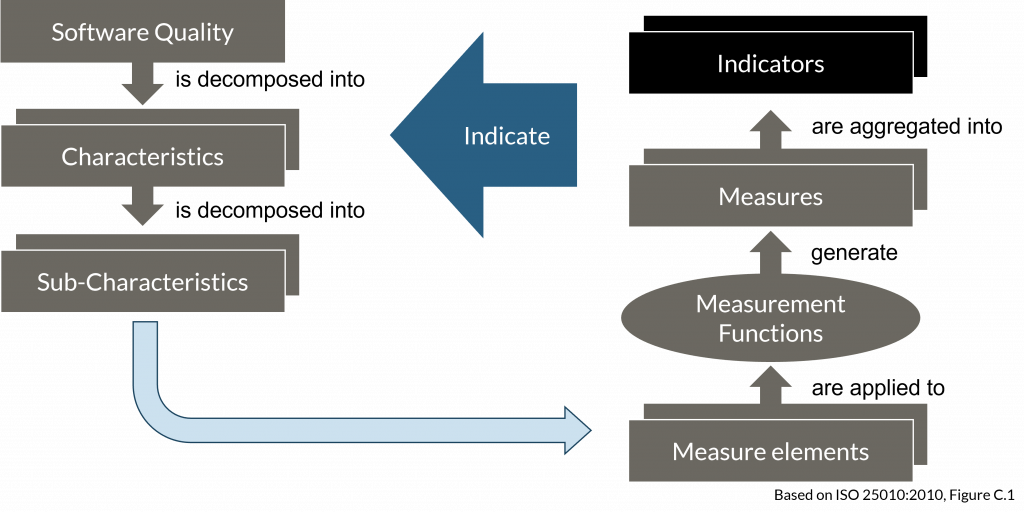
Indicators can aggregate measures over multiple levels, tools, work products, etc., but can also aggregate and overlap with other indicators. Their usage enables focusing by accumulating information (providing an abstract overview), while highlighting weak spots.
Additionally, we must define target values for our measures and indicators. These target values can be absolute, relative, estimates, fuzzy terms like “as low as possible”, or even “TBD“. But without these values, the degree of fulfillment cannot be judged.
| Characteristic | What to measure | How to measure | Target value |
|---|---|---|---|
| Functionality | Functional requirement | Verification criteria | Expected values |
| Performance | Response time | Worst case response time | 100ms |
| Average response time | 10ms | ||
| Portability | Platform dependence | Use of platform specific extensions | as low as possible |
| Maintainability | Documentation | Comment density | ≥ 0,2 |
| Code complexity | Cyclomatic complexity | ≤ 10 | |
| Nested levels | ≤ 4 | ||
| Test completeness | Requirements coverage | Trace links from test cases (TC) to requirements (Req) | 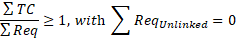 |
| Test case (TC) reviews performed | 100% of TCs covered by review | ||
| Structural coverage | Statement coverage (during Unit and Integration Testing) | 100%, there of at most 10% Covered by Analysis |
Now, we should have everything at hand to measure our software quality. Let us take a look at an example.
A good starting point for things we can measure concerning code are the HIS-metrics. The HIS-metrics are a set of metrics defined by the “Herstellerinitiative Software” (the manufacturers’ software initiative), the former software, process, and quality initiative of German automotive manufacturers. It still represents one of the most complete and widely applied collections of code metrics, not only in the automotive industry. This is not only due to the applied metrics but also because it comes with target values for most of the metrics (some of the contained metrics are for documentation only). Some of the measures listed above are directly taken from this collection, like the comment density, the cyclomatic complexity, and the nested levels (together with their corresponding target range). And as you can see, the used measures do not always match the characteristic we are looking for. Thus, we can aggregate the measures into indicators, in this case, „Complexity“ and „Documentation“. These indicators then show us if we have reached our expectations on „Maintainability“.
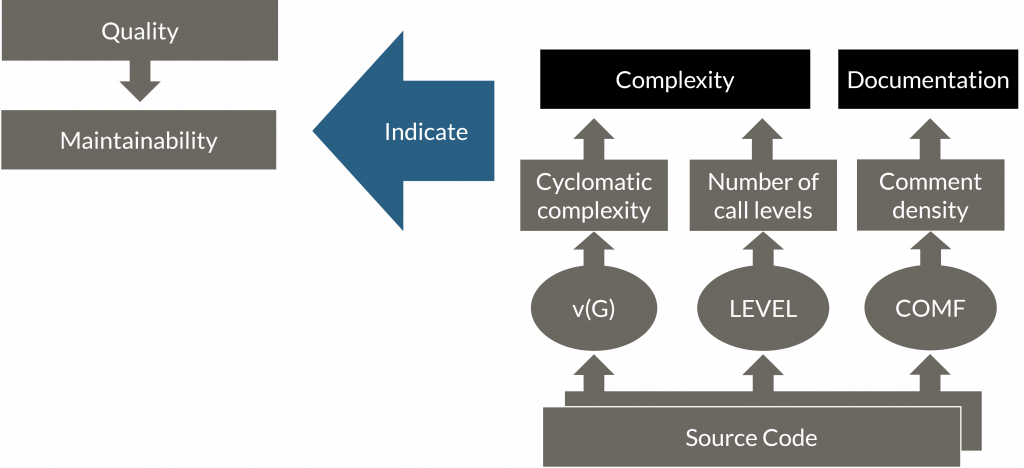
Depending on the target values and how we aggregate the indicators we get a different quality. An easy way to aggregate is to determine the average overall values. E.g. if we have achieved 90% (degree of fulfillment) for the cyclomatic complexity and 80% for the number of call levels, this could result in a complexity of 85% ((0,9 +0,8) / 2), and so on and so forth. In the end, we get a software quality rating for the whole development.
But doing this only once in a while is not very purposeful. In this way, we could only determine how good or bad we are, but do little to change it. Therefore, we should ensure that our quality is maintained.
In my next blog post “How to maintain software quality?“, I will talk about how this can be achieved. I’m certainly not giving away any secrets when I say that Continuous Integration plays an important role in this. But at least as important as maintaining quality is the adjustment of quality, which will also be addressed.