Like clones from a famous galactic franchise, source code clones can be dangerous if you let them multiply:
- They carry bugs, which then also multiply.
- Clones artificially inflate code volume.
- Maintenance becomes frustrating and time-consuming.
But unlike the movies, there is no magic command to control them all. There are two main classes and they are tracked and dealt with differently.
The two main classes of code clones
Textual clones
These are “dumb”. Often being introduced as a result of an unfortunate copy-paste. They can be detected by simple text search functions.
Here’s how! To find the interesting ones, you should:
- Ignore blank lines and comments
- Set a size threshold to avoid finding thousands of small, insignificant clones
- Decide what percentage of duplicated code qualifies as a clone
All that being done, you are now able to easily find textual clones. Here’s a quick example:

Algorithmic clones
These are smart. They reflect architecture mishaps or insufficient knowledge of existing code.
You can’t find them by looking for similar texts, because they hide. Either by changing their function and attributes names or by handling different data types. The smart way to track them is to analyze a symbolic representation of the source code and look for algorithmic duplicates.
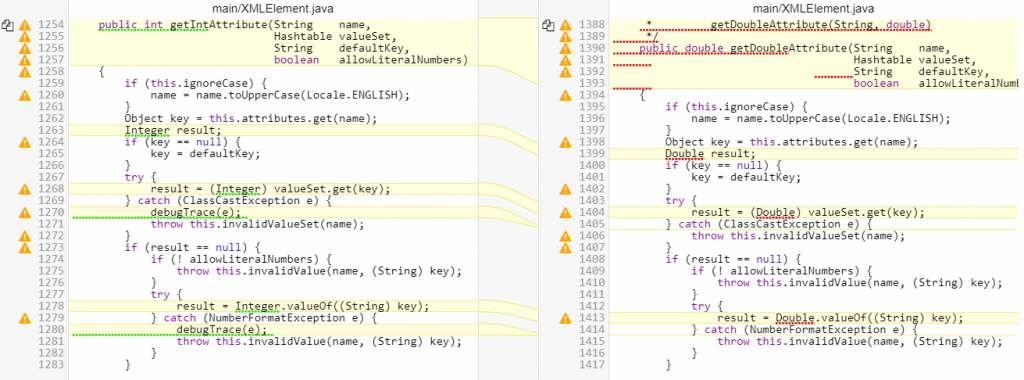
Below is a typical algorithmic clone with textual cloning in white and algorithmic cloning marked in yellow.
But wait, that’s not all!
Finding all these clones (dumb and smart) doesn’t mean you have to handle them equally.
Depending on your objective, you might want to focus on:
- Clones with the least bugs, minimizing your effort
- Or on the contrary the most buggy clones, resulting in a sanitized code
- Or even clones on heavily tested code, improving reliability and test optimization
Finally, throw into the mix the fact that not all code needs the same level of attention and you’ll understand that battling clones requires not just finding them. Battling clones requires a strategy.
Now what?
We now know that clones are out there, carrying bugs, inflating the code, and potentially making development harder and longer.
We also know what to look for (textual or algorithmic clones), and that we should apply some kind of strategy.
But how?
Fortunately, there are solutions to do just that. We’ll get to this in the next post Clone spotting: Find code clones with their DNA – to help you win the clones war. 
References & further reading
- “A Systematic Review on Clone Detection” by Qurat Ul Ain, Wasi Haider Butt, Muhammad Waseem Anwar, Farooque Azam, Bilal Maqbool in IEEE Access, Volume 7, 22 May 2019
- “The Survey of the Code Clone Detection Techniques and Process with Types (I, II, III and IV)” by Gundeep Kaur, Er. Sumit Sharma in International Journal on Future Revolution in Computer Science & Communication Engineering, February 2018
- “Various Code Clone Detection Techniques and Tools: A Comprehensive Survey” by Patriksha Gautam, Hemraj Saini in Smart Trends in Information Technology and Computer Communications, Springer Singapore, December 2016
- “Comparison and evaluation of code clone detection techniques and tools: A qualitative approach” by Chanchal K. Roy, James R. Cordy, Rainer Koschke in Science of Computer Programming, May 2009
- “Duplicate code” in Wikipedia