

Software quality monitoring has many dimensions: the quality of data produce a deep landscape to explore, and passing time gives it additional meaning. But there’s something missing in this picture, or rather someone: you. Software quality for the team is not just a matter of fancy colorful charts. In a way, quality data should be addressing your concerns, talking to you.
Why use a software quality aggregating tool?
There are so many tools already competing for our attention in the development cycle, with specific objectives:
- Checking our code: is it clean and readable?
- Looking for violations of rules: is the code compliant with a given list of standards?
- Testing the code: do tests pass? From unit, integration, system, to regression, performance, load, stress and more
You probably already use these kinds of tools and have read their specific dashboards, reports, or logs.
As efficient as they all are, they are different, which means they each have a personal way of reporting results and raising alerts. You could become fluent in all the forms of communications these tools use, but what happens when a new tool comes along, or when an existing tool changes something?
Introducing an aggregating tool is not just a matter of avoiding to learn many tools’ “languages”, but it’s a way to introduce better adoption of the tool data.
Using a single tool to report all these data, with a language you are comfortable with, helps you;
- Focus more on the actual meaning of the result (spending less time remembering how to read them)
- Learn something important about your project
- Act on your project, because the original data talked to you in an effective way
So, an aggregating tool’s first objective is to provide “data meaning”, not just do “data mining”. That is where Software quality can really talk to your team.
Keeping the whole team in the software quality loop
An aggregating tool is just a means to an end.
It’s comforting to continuously aggregate data from 10 specialized tools, producing meaningful data every day. But if you don’t check and monitor them, that meaning is lost.
It’s like that crazy tasting video, you can’t make good decisions if you’re not part of the project loop.
Of course, there is a balance between automation and team involvement.
- Must automate: Repetitive and ‘dumb’ tasks such as retrieving data from several tools, and translate them into a common language.
- Should automate: Compute indicators relevant to your industry, standards, and project context. Analyze compliance to objectives, check if trends evolve as expected, raise alerts.
- Should not automate: Justify deviations, confirm or reject compliance, make project-level decisions.
And so, finding the sweet spot can be a matter of maturity: if you have quality checks in place, they should be part of the automated process, as the team already agrees on their definition and usage.
If you don’t, maybe it’s better to first save time on the data crunching part. Then use the extra free time to properly decide on the quality strategy.
In any case, the whole team should be part of the quality monitoring process. Even more, your needs should be understood, and some questions anticipated.
Efficient software quality is user-centered and role-based, to ‘talk’ to each team member according to their role, and their actions in the project. Indeed, a developer, quality engineer or team manager working on the same project don’t expect the same level of detail on the project quality and have different needs on how to monitor it.
See it in action
Based on our analysis of several GitHub open source projects, let’s see what user-centered monitoring can look like.
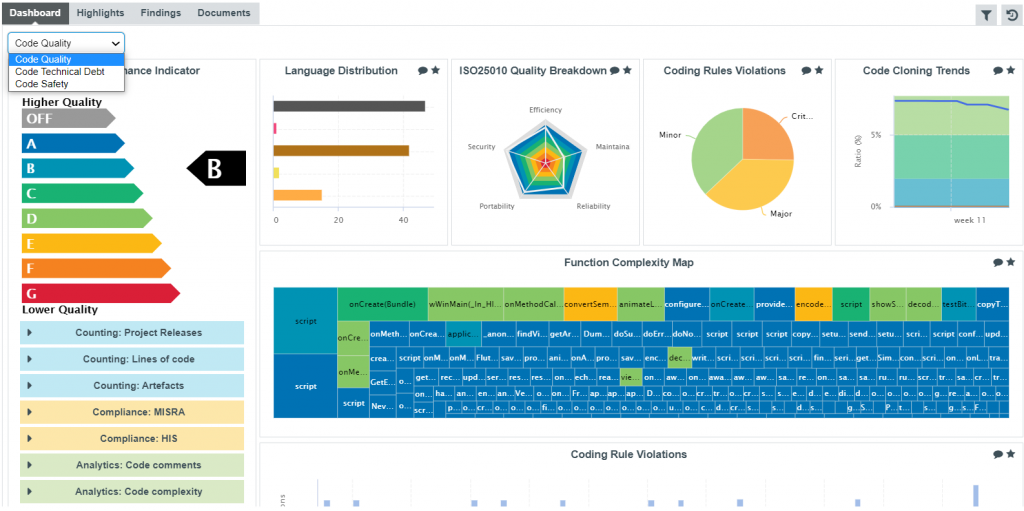
First example: Provide different analysis angles
The dashboard system provides several views dedicated to different ways of navigating the project: by quality indicators, Technical Debt analysis, or Safety check.
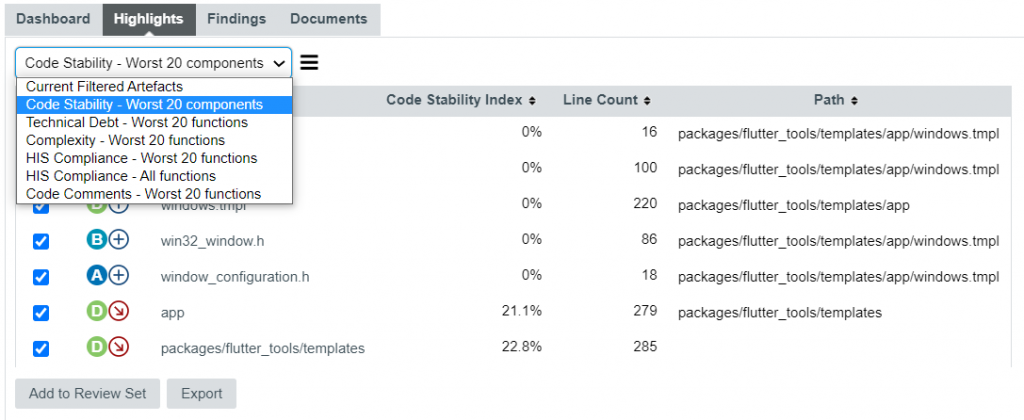
Second example: Provide user-centered software quality filters
This feature called ‘Highlights’ is here to provide advanced filters on the project, by looking for components with given characteristics.
In the example below, we found project components that have recently been modified, based on the analysis of the modified, added, or removed code lines.
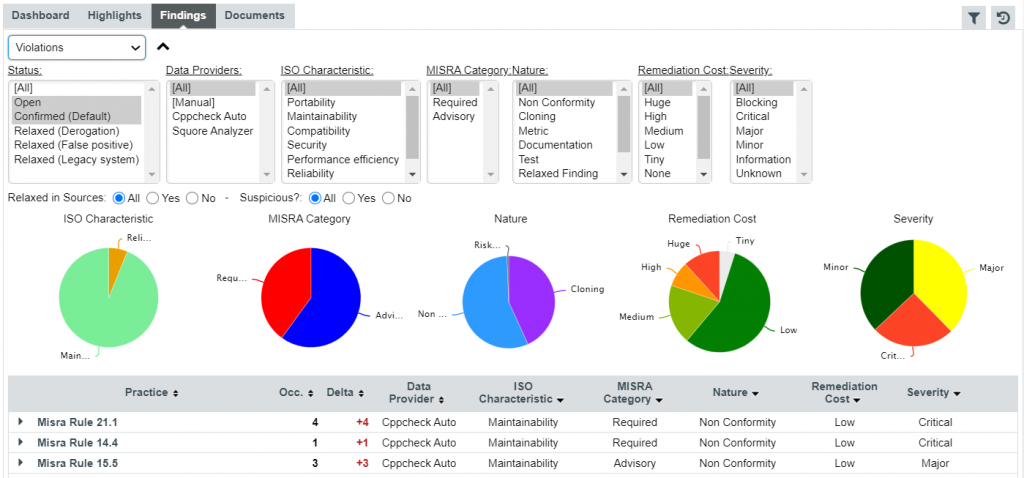
Third example: Provide fine-grain interaction
The ‘Findings’ page aggregates rule violations from different tools in a single view. From this page, it is possible to filter violations according to their category, severity, and status.
Once on a finding, it is possible to justify it impacting the standard compliance, in an interactive review mechanism.
You can also analyze coding practices, and check which rules are no longer violated (or on the contrary newly violated).
In the end, you don’t need to become a quality specialist, and know all aspects of the quality assessment mechanism. As a team member, with easy access to data, and to relevant indicators, you become a software quality practitioner.





1 thought on “Software quality for the team: You talkin’ to me?”
thank you