
What is it?
Keras is part of the Artificial Intelligence family.
Its official website describes it as “an API designed for human beings, not machines. Keras follows best practices for reducing cognitive load: it offers consistent & simple APIs, it minimizes the number of user actions required for common use cases, and it provides clear & actionable error messages. It also has extensive documentation and developer guides.”
We include Keras systematically in our software quality monitoring of GitHub projects.
Important note: If you notice that projects latest versions are not visible in our monitoring, it’s normal. We regularly update our base, but not continuously, to leave time for the code to properly evolve.
So come back regularly, as new versions are added to our monitoring, and trigger new analyses.
Big picture – overall view on software quality in Keras

Project size
Keras is a Python only project.
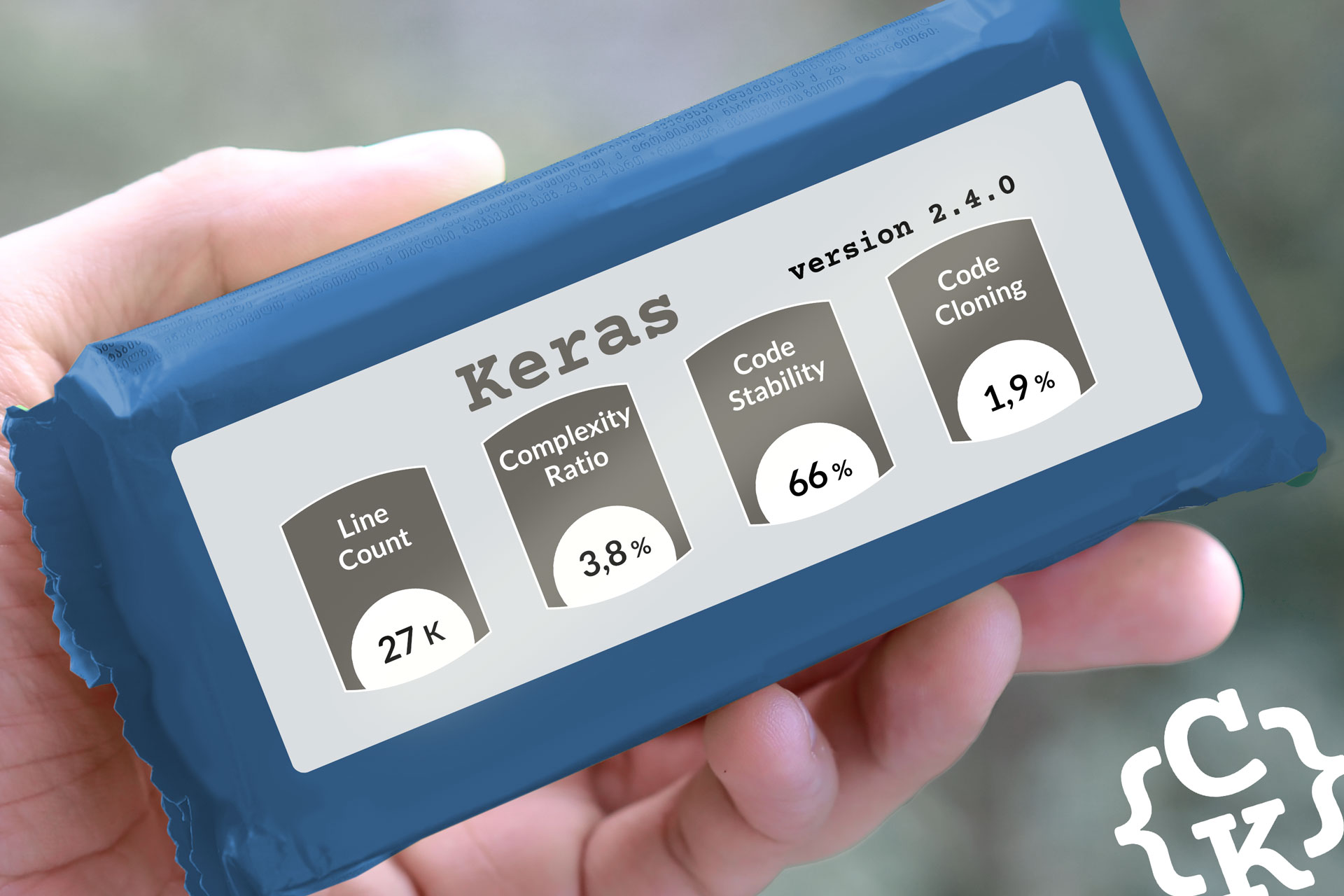
The analyzed version (2.4.0) counts :
- over 27k lines of code (about 20k of which are effective code)
- 160 files
- 1302 functions
Keras – Project complexity
- This project has a low complexity ratio
For version 2.4.0, complex functions represent less than 4% of the code volume. - The complex function with the most nested levels has five, and its control graph looks like this:
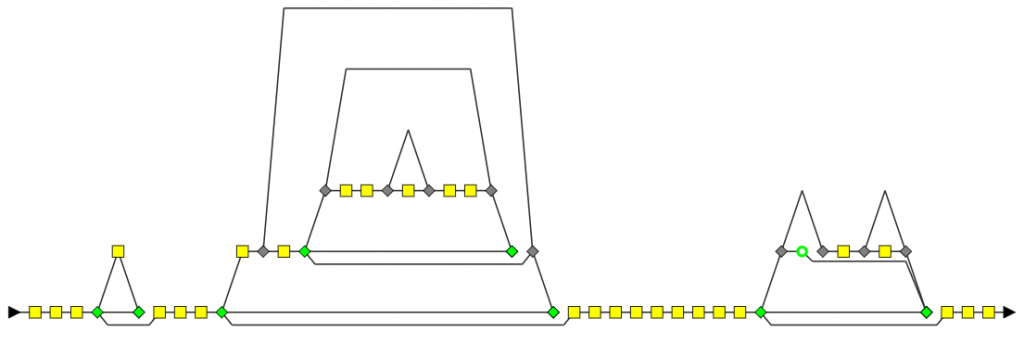
- The bigger complex function has 207 lines of code (155 effective lines)
Keras – Technical Debt
- The overall Technical Debt is 22 days
- The “New Technical Debt” (for added code) is 2h45′
- The “Modified Technical Debt” (for modified code) is 5 days and 3h
- The “Unchanged Technical Debt” (for unmodified code) is 16 days and 1h
More about measuring and monitoring technical debt
Software quality analysis: Why did we focus on Keras?
If we look at the project trend indicators, they all strongly decreased since last version.
Having such a simultaneous trend indicates a drastic change in the project. Let’s investigate…
Exploring the dashboard
Opening the Code Quality dashboard for Keras version 2.4.0, what can we look for?
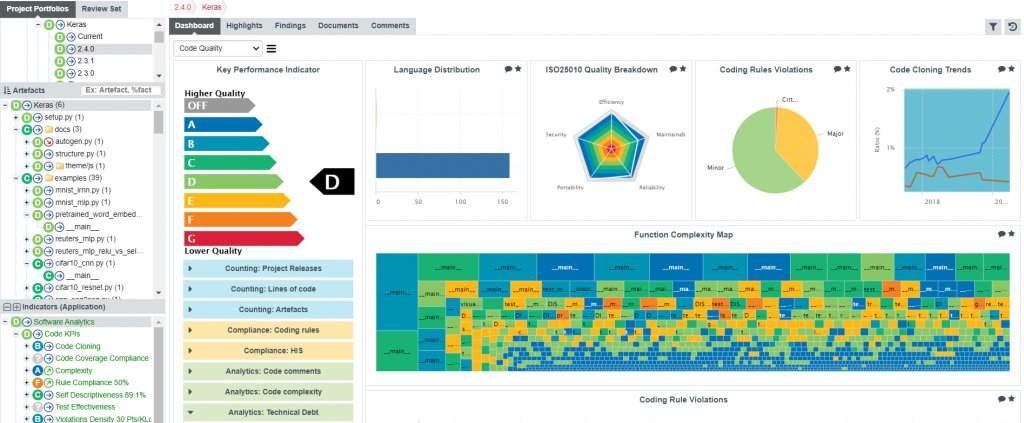
- First, since a big variation of code stability was detected, we can open the “Counting: Lines of code” table.
This table provides counts produced by the code analyzer:- Line Count: All lines, from every analyzed file
- Source Lines of code: Same as before, ignoring the comment
- Effective Lines of code: Same as before, ignoring lines with characters such as braces
- Executable statements: Available because the analyzer detects the code statements
Note that the “Artefacts” tree on the left breaks down the whole project into folders, files, classes (when available), and functions. Since we have selected the topmost artefact (the root of this tree), we get the counts for the whole Keras project.
Selecting a single file would have refreshed the table accordingly.
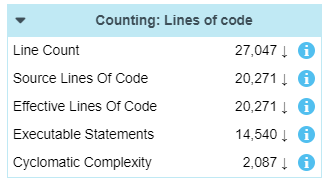
By the down arrow next to them, we can see all these counts did indeed decrease, as expected.
To see how much they decreased, we click on the arrow of the first count (Line Count).
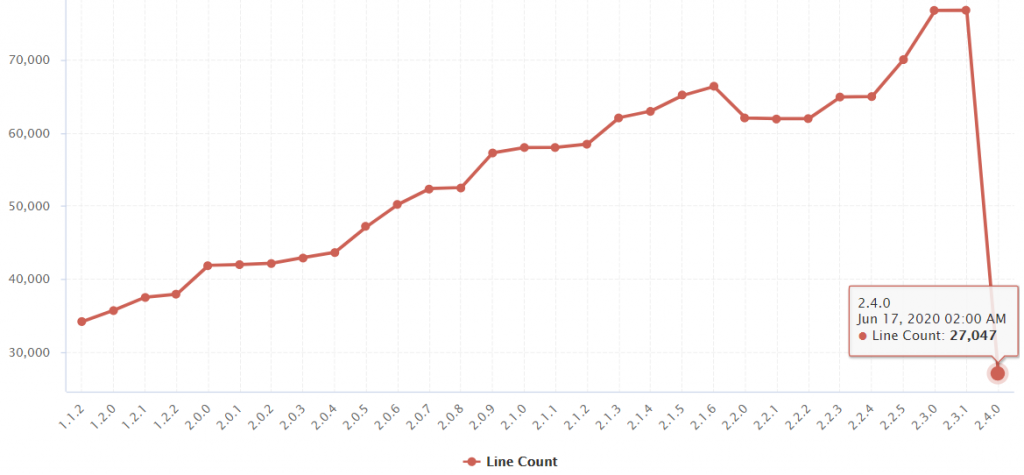
The chart provides the trend of the “Line Count” metric for all analyzed versions of the Keras project.
We can observe the line count slowly rising, which is not unusual for a living and evolving project.
But then, there is a sharp drop at version 2.4.0, from 76k lines down to 27k lines, more than 60% decrease of code.
That is not so common for a project.
So, either there was an epic fail in our counting algorithm, or the code did really shrink, and fast.
The winds of change
Confident in our code analyzer, we continue our search in the Releases page for Keras, and find out that a significant adjustment had been decided from version 2.4.0, as development “discontinued multi-backend Keras to refocus exclusively on the TensorFlow implementation of Keras.”
As we’ve seen, drastic code change as this one can have immediate impacts on the trend indicators. These indicators are also sensitive to smaller changes, but this first example is a good way to start getting familiar with our approach.
We’ll continue exploring projects from our showcase in future “Software Quality Analysis” posts!


2 thoughts on “Software quality analysis: Keras version 2.4.0”
Hello Flavien,
Do you have any sample GitHub project ?
Thanks
Hi Rakesh,
Keras is indeed a GitHub project we launched our analysis on.
If you want to discuss further how we performed this analysis, please contact us, we’ll be happy to continue the discussion
https://www.coderskitchen.com/contact/
Regards