In this second part of my blog post about test case prioritization, I describe why and how I extended my project’s test scheduler by dynamic re-prioritization.
In the first part Test case prioritization – go for an easy approach I explained simple techniques that can be used to statically prioritize test cases. The idea is to order tests in a test suite such, that those tests are scheduled first, that have the highest probability to fail (i.e. to find bugs).
Motivation
The software under test of my project runs on several product variants, which all are subject to testing. If a test team member presents a new bug found to the developers, there are typically two questions that we need to answer:
- Which of the product variants are affected?
- Which other features, related to the failing one, fail as well?
To give developers a jump start into debugging, hence testers should execute similar tests before contacting the development team. Ideally, the automatic test scheduler should be smart enough to do that. The following paragraphs describe how I implemented such a “smart” test scheduler by simple means.
Dynamic test case re-prioritization
Academic research on dynamic test case reprioritization aims at scheduling those tests first, that have a high probability of failing. Some of these methods extract data from (many) previous test executions with the help of artificial intelligence: If in the past two tests A and B (almost always) failed or passed in parallel and A failed right now, then the priority of B is increased – because it will fail with high probability. To me that for sure increases the number of failing tests per time, and yields a higher score for the approach presented by the research team, but the root cause of the failures of A and B is likely to be the same. Thus, I doubt that this helps finding more bugs in shorter time or assists developers in debugging.
Other dynamic methods, however, offer exactly what my project needed: test re-ordering based on the similarity of tests. Inspired by a research paper, I implemented the following algorithm in our test environment:
- If the verdict of the test just executed is FAILED, then increase the priority of the most similar test. In our case this is a test for another product variant. This is the “smart” test selection, that may help developers
- If the verdict of the test is ERROR, then decrease the priority of the 10 most similar tests. This may help avoiding useless test executions when a measurement device does not react, for example.
- If the verdict of the test is PASSED, then search for the most similar test. If the priority of that test has not been increased during this test campaign, then decrease its priority. This will increase the diversity of the scheduled tests.
Test signature
To assess the similarity of two tests, some researchers analyze textual test descriptions using methods implemented in plagiarism checkers. But it does not have to be that complicated. In my project all our tests follow a certain pattern:
- Bring the system under test into a defined initial state.
- Set one or more parameters of the system under test to a certain value.
- Measure the effect or read certain parameters of the system under test.
- Iterate steps 2 to 3 and finally stop the test execution.
All our parameters have unique identifiers. The list of tuples (parameter id, parameter value) is a very good characterization of a test – it is a kind of “signature”. Similar tests (that test similar features or identical features on other devices) have similar signatures.
Test similarity
My test scheduler assesses the similarity of two tests by comparing their signatures with a very simple similarity metric: the Jaccardian Similarity. Let A and B be sets of the aforementioned tuples, then the Jaccardian Similarity J(A,B) = |A ∩ B| / |A ∪ B|. This metric is 100%, if both signatures set the same values on the same parameters and read the same parameters.
There is one important enhancement you have to implement to make this metric meaningful when dealing with short tests: disregard the test initialization in the signatures. Otherwise, you might end up with bogus values for this similarity metric.
Results for my approach to prioritize test cases
The combination of the static and dynamic test case prioritization techniques presented in this and my previous blog post works for any software-driven system under test, including distributed systems and systems containing FPGAs. I regard it simple to implement but nevertheless, it has been an effective improvement in my test project.
My project is very long-lasting. We have been extending and improving the software for 12 years and our bug tracker contains more than 1200 bug tickets. For approximately 25% of new code changes the technique, described in the paragraph “Painting Black Box Tests White” finds corresponding tests. To me, the effectiveness of this kind of test impact analysis is out of question because it directly relates the changed source code to tests.
To assess the effectiveness of the other implemented static and dynamic test case prioritization techniques, I have applied them separately to software packages and made plots, that visualize the effectiveness. In academic research, you would analyze hundreds of test runs. I was happy with a hand full because in my project testing one package takes 3 to 4 days – that is why test prioritization is so badly needed. In the plot below you see such a visualization of a test run on one of my test systems. This test system executed 350 tests concurrently with other test executions on other test systems. The x-axis depicts the test schedule. In the chart’s y-axis you see a one when a test failed and a zero when it passed. Ideally all test failures, i.e. all ones, should be found at the left end of the plot – that means all failed tests were scheduled as early as possible. We can conclude from the plot that our test schedule was not perfect but far better than random test execution. In the visualized test run we see a comparatively high number of test failures. That is because one of the bugs affected a core function of the system under test.
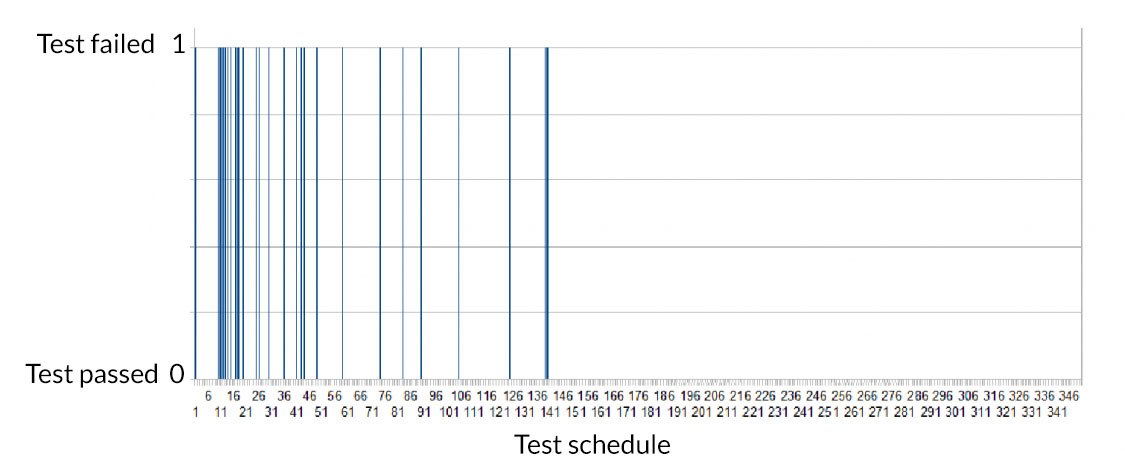
Even though it has been a success for my project, there are certain shortcomings that need to be considered: The effectiveness of the static prioritization technique presented in the first blog post in the paragraph “Painting Black Box Tests White”, is strongly limited by the number of usable issues found in the bug tracker. As a matter of fact, the data in the bug tracker gets invalid, if the software architecture changes. Finally, all test impact analysis techniques may fail, if bugs are introduced by changes of the software build, by a change of application data, or by configuration management issues.
Further readings
- Test case prioritization – go for an easy approach (First part of this blog post about test case prioritization)
- Dipesh Pradhan, Shuai Wang, Shaukat Ali, Tao Yue, Marius Liaaen: “REMAP: Using Rule Mining and Multi-Objective Search for Dynamic Test Case Prioritization“. 2018 IEEE 11th International Conference on Software Testing, Verification and Validation.
- Breno Miranda, Emilio Cruciani, Roberto Verdecchia, and Antonia Bertolino. 2018. FAST Approaches to Scalable Similarity-based Test Case Prioritization. In Proceedings of ICSE ’18: 40th International Conference on Software Engineering, Gothenburg, Sweden, May 27 – June 3, 2018 (ICSE ’18).
- Improving test efficiency: 7 steps to cope with the “testing is taking too long” problem