Which are the best methods to reduce efforts in system testing? In this second part of the Coders Kitchen interview, system testing experts Hans Quecke and Simone Gronau dive deeper into the methods of model-based system testing. Also check out the first part: Traditional vs. model-based system testing. Interviewer: Daniel Lehner from Johannes Kepler University, Austria
As a product manager at Vector, Simone Gronau focuses on testing concepts for system tests. In particular, model-based testing accompanied her since her master’s thesis in this area.
Hans Quecke is working at Vector for more than 25 years. Currently, he is responsible for the concepts of Vector testing tools and the development of vTESTstudio.
How to reduce efforts with model-based system testing
D. Lehner: How do you think that model-based system testing can be used to reduce the effort in system testing?
S. Gronau: The main point for reducing effort is usually increasing the maintainability of your system tests. By simplifying the representation of tests using model-based methods, changes can be applied easier. As system requirements tend to continuously change in practice, this reduces a lot of effort. Additionally, consistency throughout several tests can be ensured by defining abstract building blocks that can be reused for different test cases throughout a model. Changes to a building block are of course automatically propagated to all places at which it is used, further reducing maintenance effort.
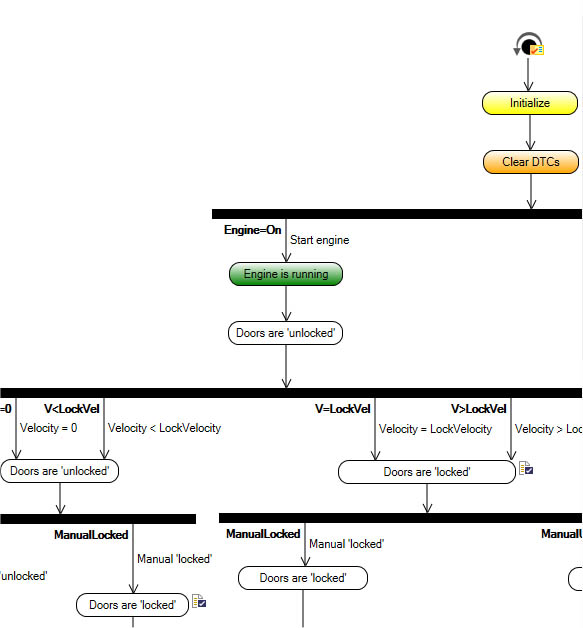
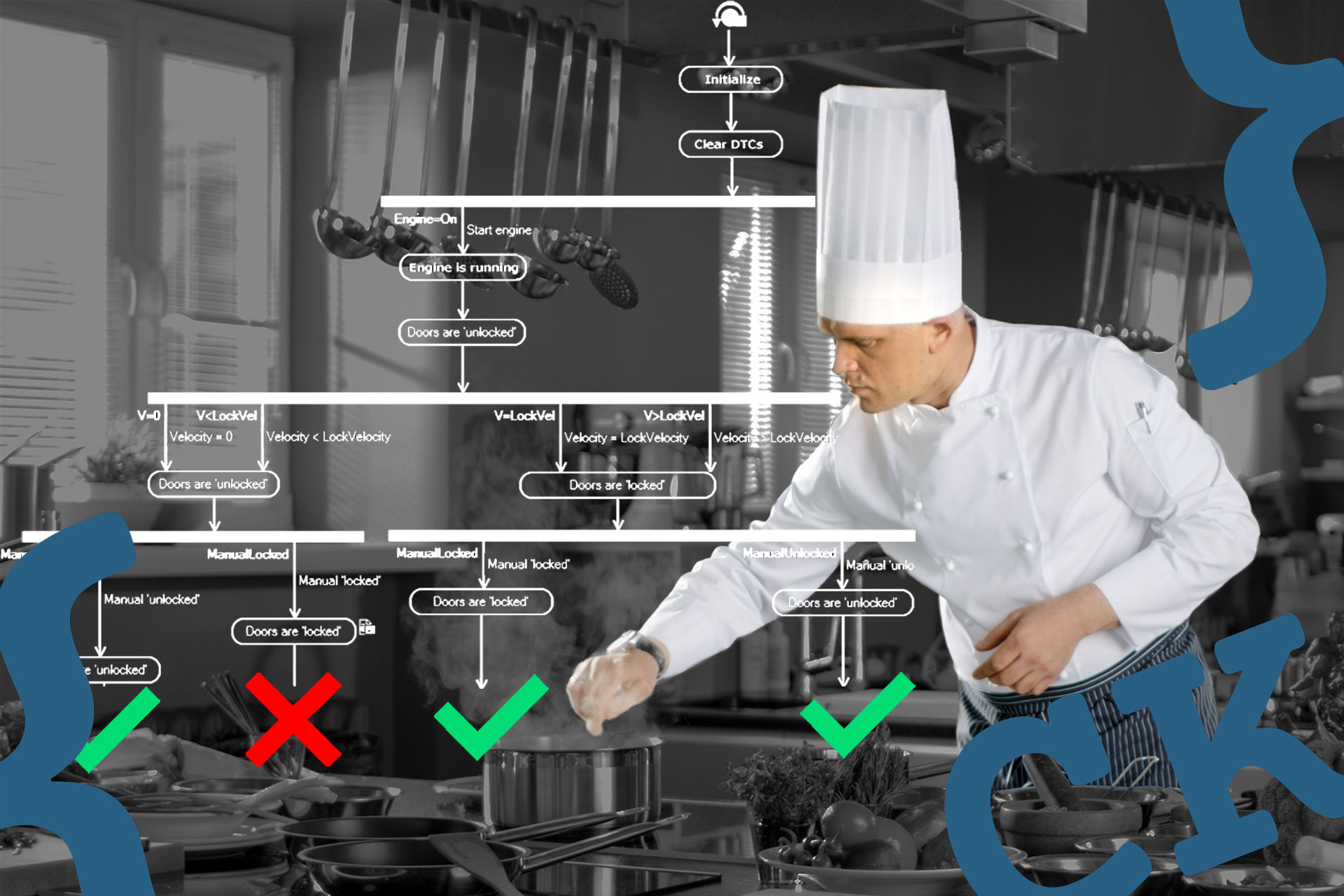
H. Quecke: Let me add here that by defining several test cases in the same model, similarities between these test cases also become evident. Usually, you have a base sequence that shows the standard way of executing your system in a particular context. This base sequence however varies based on different testing scenarios. Thus, you will most likely have several tests that share common execution sequences but also have specific parts. Dedicated graphical elements in the test notation enable the test designer to model common parts and specific parts in an easily understandable way.
S. Gronau: This becomes particularly relevant once we start talking about testing different variants of a system. By defining all test variants in the same model, we can easily see that the newly added variant needs to be considered in every part of our model. Reversely, it becomes evident whether all variants are already covered by test cases by simply checking these paths through the model.
H. Quecke: Another aspect that I find particularly relevant for reducing efforts is the code generation feature of models, meaning that no one needs to care about writing or understanding code for system tests anymore. Why is this such a great feature? Because it enables people with different backgrounds and roles to easily communicate with each other. Finally, they have a common ground that they can use to discuss and define system improvements, in a graphical notation that is understandable by all stakeholders. Creating such a common understanding even reduces communication. For example, if a test fails, the requirements engineer can start investigating the reason for this failure, without the need for an extra developer to explain to the requirements engineer what’s actually going on in the test code.
In some cases, we have even seen that using model-based methods reduced the number of people involved in a system testing process. As people have a common way of communicating, there is no person needed to translate information from one document (e.g. a word document where notes on test cases are put together with high-level requirements) to another (e.g. the test specification used by the developer writing the code), or no one needs to stupidly convert a formally defined test specification into code. In a model-based system testing environment, testers can actually talk directly to requirements engineers in order to define, generate, and execute test cases.
S. Gronau: I fully agree with this point – we even see in most projects that people start to develop a set of best practices together to use the graphical notation provided by a model-based testing tool in the most understandable way. We often see people developing their own patterns for particular checks or decision points in their models. One best practice we also commonly see is that people use color-coding of elements to visualize different paths in a model that lead to a special kind of test scenario. For example, the standard way to perform a certain action is often marked in green, and then based on this standard case, several extensions that should lead to an error are marked in red.
D. Lehner: Is there a customer example that you can use to show us these advantages in practice?
S. Gronau: Definitely! I recall one project in particular, where our customer had a multi-level testing process in the beginning. Domain experts defined system requirements, which were then transformed into a test specification document with diagram-like visualizations. These diagrams were then broken down manually into concrete test cases and transformed into test code.
At the end of the project, the domain experts defined their requirements directly in a test implementation tool using a graphical, model-based representation. The tester enriched this abstract representation via the specific system I/Os, and then executed the automatically created tests directly on the system.
D. Lehner: Wow – that sounds like we can gain a lot of efficiency by using the right tooling!
The perfect system testing process
D. Lehner: To wrap up and summarize our discussion, can you quickly summarize what a perfect system testing process would look like from your point of view?
H. Quecke: Well at the beginning of such a process, we have some sort of requirements. As a first step, my advice is to implement the test cases for one requirement in a test model. After that, this test model can be extended to include further requirements. The main point here is that we have one model that covers a whole set of test cases, instead of decoupled test cases that do not enable any reusability or seeing relations between different test cases. This is how we can make system testing maintainable, and easily bring people with different backgrounds together to find a common understanding of how a given system will be tested.
S. Gronau: There’s not a lot to add here. Just let me point out that usually, it’s also not feasible to put all your requirements into one document, because the resulting test model will be too big to understand. In the end, it’s about meeting this sweet spot in the middle, where you can still easily see the relations between the individual requirements and test cases. Therefore, it makes sense to start out by clustering your requirements at the beginning of the testing process. Then, similar requirements can be put in the same model, but different clusters of requirements should also be split into different test models.
D. Lehner: So as a takeaway for you, let me summarize what we have learned in our two interviews on system testing:
Reduced effort using model-based system testing
- Traditional system testing involves many people talking to each other
- Model-based tooling drastically reduces these efforts. It offers you
(i) a common document that all stakeholders can use to create a shared understanding of what should be tested, and
(ii) the visual representation makes it easy to identify required test paths and maintain them long-term. - When creating model-based system tests, you create a test model by connecting reusable building blocks to represent a set of test cases to be executed on your system. The required code to execute these tests is then automatically generated from this test model.
- The key here is to group similar requirements into the same test model. In the end, you want to hit this sweet spot at which you can leverage commonalities between different tests in your model, and have a good basis for discussion, but it’s still fast and easy to grasp what is going on in your test model.
Start with model-based system testing now
Product information: Model-based system testing with vTESTstudio
Further readings
- Traditional vs. model-based system testing (first part of this interview)
- Testing levels: From unit test to system test
- System testing in virtual environments
- Testing IoT systems: Challenges and solutions
- More publications from Daniel Lehner