

Turmoil has engulfed the Coders Kitchen. Right now, we will have our first post about How Fuzz Testing or Fuzzing is establishing itself as the number one technique for highly automated software testing. Or to be more precise: How does automatic value generation work in Fuzzing?
I my last post I shed some light on the Why – in my introduction into ‘Fuzzing – The Prequel‘.
And what is with all those fuzzing buzzwords floating around? I mean there are a metric ton of them, right?
Random based Fuzzing, Evolutionary Fuzzing, Mutation based Fuzzing, Structure aware Fuzzing, … (that list just goes on and on).
Do not fear – we will talk about all of them (and more beside) today!
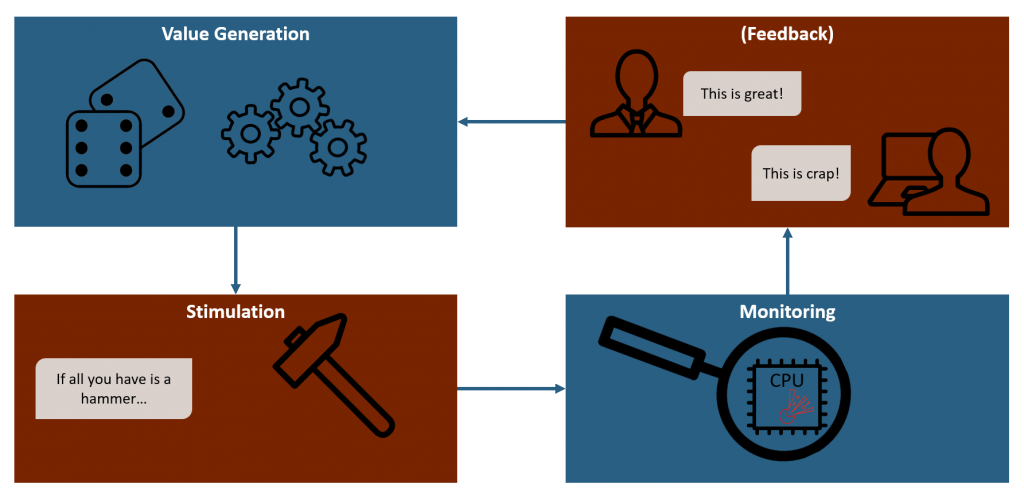
Remember the Fuzzing cycle picture from before? This post is all about the first stage.
Most of you will probably be most interested in this one. Why?
Because automatic test case generation is damn cool – that’s why!
So let us jump right into it, shall we?
1. The general value generation approaches
If you were to break all of the following down to some core building blocks, you would get the following two principle approaches. All the more advanced forms use some variation of these or even combine both in some fashion.
- Generator based Fuzzing: The Fuzzer creates test values from scratch. It does not use any kind of reference input – although it may use meta information. Sometimes it is also called generation based Fuzzing.
Think of it like some hero (or villain) is building a super-powerful robot or cyborg from scratch – bonus points if he does it in a cave. - Mutation based Fuzzing: The Fuzzer modifies existing values to create new ones. This obviously requires some kind of baseline input. We call this baseline the corpus or seed of the Fuzzer.
This is like someone getting bitten by a mutated insect and developing super powers or someone from a secret super soldier program.
2. Black, white, grey box Fuzzing: Cats love them all!
Sad news – I will not talk about cats in this section (or post for that matter). Boooh!
Rather, let’s talk about a commonly used distinction between Fuzzers: whether they follow a black box or white box approach (or maybe something in between).
So, what’s with all these boxes?
As usual: It depends.
In particular, there are several possible definitions for white vs black box Fuzzing. Grey box is at least somewhat consistently defined as “something in between true black and white box” – with respect to the writer’s respective definitions of those.
In general terms, black box defines a system where we cannot look inside and see what is happening within. We only see what is going in and coming out. A white box on the other hand allows us to see all (or at least most) of its inner machinations. So, calling it a transparent box would actually make a whole lot more sense, but oh well…
Now, various sources differ in how strict they define those two extremes.
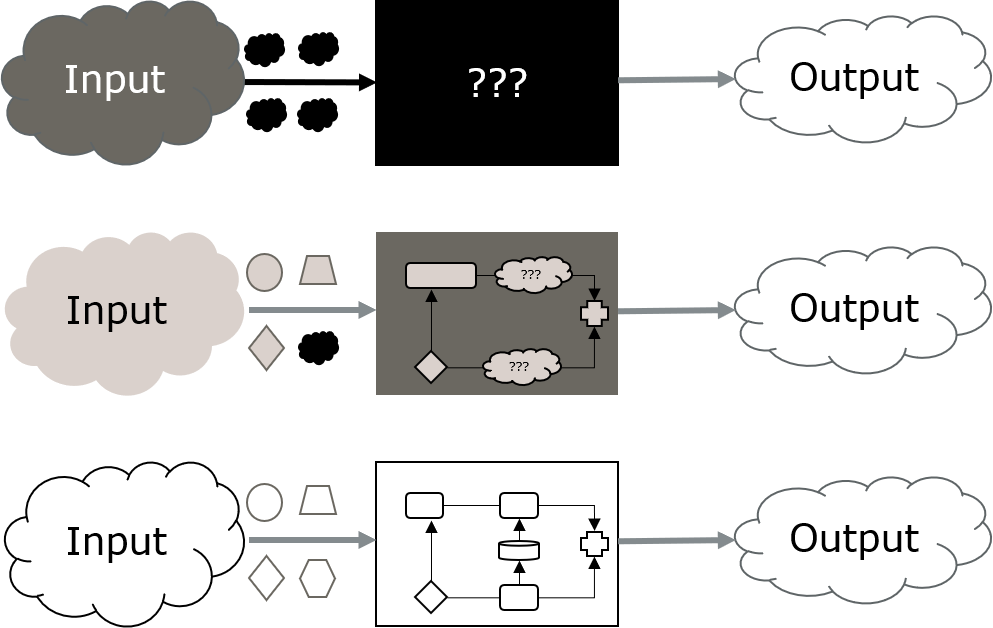
No definition is like your own definition
I want to use a very straight forward definition here, which closely matches with the prerequisites of various Fuzzers.
- Black box: A system for which no additional information is available, especially not the source code.
- Grey box: A system for which only partial information is available but not the (complete) source code.
- White box: A system for which extensive information is available, including its source code and build environment.
In other words, if we can build the target from source (and thus can introduce changes), we will call it a white box.
About dumb and intelligent Fuzzers
Let’s say you start searching for information about fuzzing with your favorite search engine. Then you will – sooner or later – find the distinction between dumb (or simple) and intelligent (or smart, modern, …) Fuzzing.
But what does that even mean?
How can something as cool as automatic test value generation be considered dumb?
And what is meant with intelligent – is Artificial Intelligence in play here or something? (Ugh, please not another AI thingy…)
In the end, this distinction boils down to whether a Fuzzer uses additional information about the target or not:
- Fuzzers who make use of additional information about the target are usually referred to as intelligent.
- Those who do not (for a variety of reasons) are called dumb. A big sledgehammer if you will. If all you have is a hammer…
Personally, I consider this distinction to be of little help and will not use it.
Instead, I will introduce the actually used concepts used in real Fuzzers – this is a technical blog after all.
We don’t care much for marketing phrases – we want to look under the lid, right?
So let me open the lid for you…
3. Value generation techniques – the simple ones
There are two basic techniques that are used by more advanced variant like building blocks. Both of these are black-box techniques.
- Random based Generator: this is the most simple generator based Fuzzing approach thinkable. We simply use random values as input for the target. As I discussed in ‘The Prequel’, this approach is still remarkably powerful and incredibly easy to implement. It was also the very first real Fuzzer as introduced by Barton Miller.

- Random based Mutator: is the mutation based variant of the above. We take a known input of the system and randomly mutate it. For example by flipping a random number of bits. Or do some shifting or swapping bits around. Maybe apply some simple math on it, like adding or subtracting one.
As noted above, this technique requires a corpus (or seed) so it is also sometimes called corpus based fuzzing. Still simple and powerful. Might yield better results for complex input data than a random based generator – if a good corpus is available.
4. Value generation techniques – structure-aware Fuzzing
This generator approach uses a certain amount of knowledge about the structure of the input data. Thus, structure-aware Fuzzing falls into the grey box area. We know a bit about the system but don’t have the source code.
Maybe we know that the input is an XML file. Or that the target takes three 64-bit integers, encoded as a hex string. Maybe there is an API documentation describing a binary struct composed of three 32-bit integers, a floating point number and a dynamic list of strings.
The puzzle analogy
Imagine solving a puzzle. If all pieces were the same, you could do no better than to simply try a random piece at a time, right? But (typical) puzzles are not like that. They have different shapes and colors. If we know that the missing piece must have two nobs and should have a decent amount of blue in it, we do not need to try a yellow one with three nobs, right?
Puzzle away!
According to the structural knowledge, our Fuzzer will then create test values that conforms to the provided structure or knowingly brakes it to some degree. So for example it may generate (syntactically) valid XML – with random content. For integer or float values we might create so-called boundary values, like zero, not-a-number (NaN) and MIN/MAX. As for strings, there even is a naughty string list maintained on github, containing all kind of crazy strings, which will really make your input validation sweat.
This is a powerful technique and very good at testing the input parsing logic of the target.
On the flip side, it is not very generic (as in: at all) and pretty labor intensive. We will have to write a new Fuzzer for every input structure and data type a target might take.
5. Value generation techniques – grammar-based Fuzzing
Yet another grey box, generator based approach. It can be considered as a special case of structure-aware Fuzzing.
For this type of Fuzzer, we make use of an actual grammar of the target input.
Grammar?
We talk about Formal Grammar here rather than natural language grammar.
You know, those mind shattering things from your Computer Science classes you always wondered: “What the hell? What use has this?!”.
The one answer we all eventually learn is: regular expression.
Well, here is another one: They are amazing when it comes to creating input data.
By just following the rules of the grammer we can rapidly create input which is valid within the bounds of the grammar.
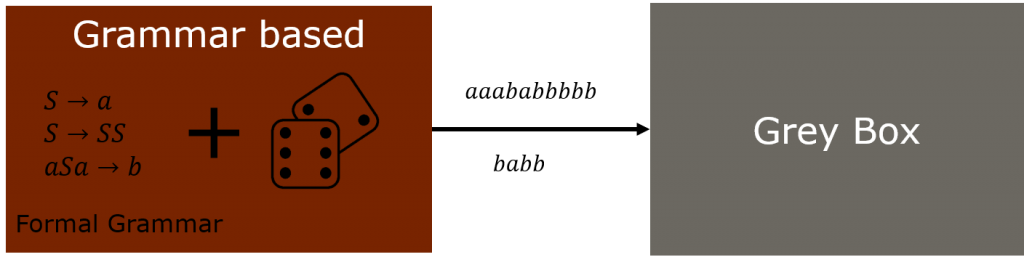
Actually, given an input grammar we can generate a program to produce such output, which always fulfills the given grammar. Or actively violates some specific part of it.
Wait, what?
Yes, we can indeed generate a program that generates output, which can then be used as test values for the target.
So, we automatically generate a generator from a grammar.
Isn’t (computer) science amazing?
Getting grammars
Of course, there is this tiny little problem that you need to have such a grammar to feed the generator with. As you may remember from your CS studies, writing a (valid) grammar is anything but easy – and it all goes out of the window when the target changes.
The good news: there is a list of (some) standard input formats for which grammars have already been written!
But what if your target does not take standard input or there is no ready-to-use grammar available?
Well, good news again!
Recently, some clever researchers came up with the idea of generating such grammars dynamically from running and observing the target program.
Come again?
Yes, we simply™ add yet another generator to the process.
It will generate a grammar used to generate the test value generator.
That’s right, Generator³ coming right up!
This is still undergoing research and improvements but has great potential as shown by the massive amount of bug bounty its creator collected from Firefox and Google within a single week.

Note however that this requires in depth observation of the target. Thus we can only do it in a white-box scenario.
6. Value generation techniques – symbolic code execution
Whew, Grammar based was a beast right? Formal Grammar, Language Theory, Generator³, …
So what if I told you we can throw even more (but different) math at the problem?
Symbolic Code Execution (also referred to as concolic execution) is a somewhat weird (but powerful!) combination of static code analysis techniques and Fuzzing. Microsoft has done some serious work in this area and uses it extensively in their SAGE Fuzzer.
The basic idea is simple enough though, so let me explain it briefly.
Symbolic code execution
- We start by executing some initial test case produced by one of the other fuzzing techniques
- While the target executes it, we tightly observe it.
- We take notes on each branch it took
- … especially why it took this branch and not the other. E.g. we note down the condition and variable values
- We then pick one of those conditions and try to negate it
- Using constraint solving on the conditional check and the used variable values
- And influence them in a way that will yield the picked condition to flip
- This guarantees that in the next test case, we will reach a new branch
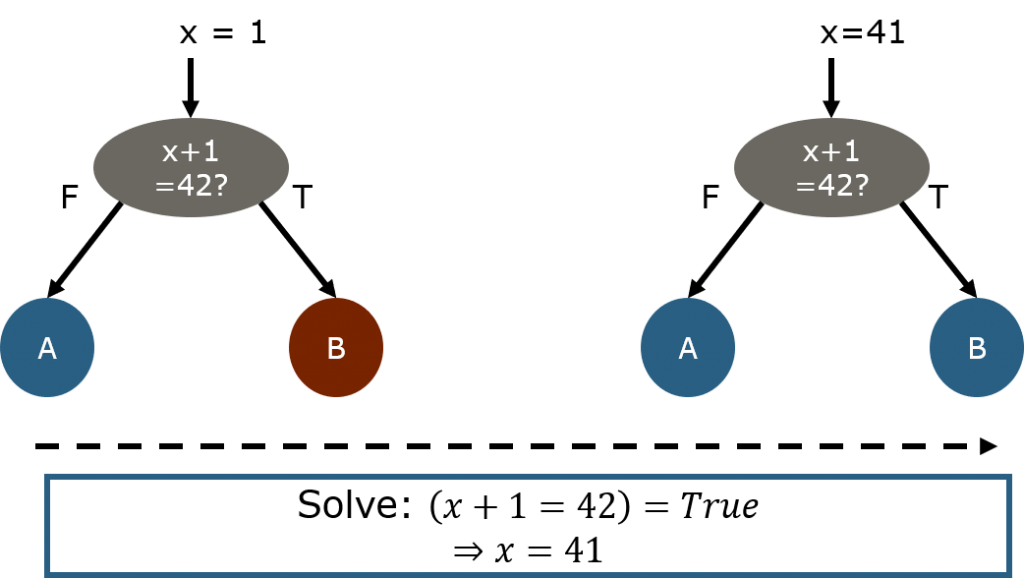
Ok. But Why?
A good question.
While very powerful, doing constraint solving as part of the fuzzing loop is (very!) computationally expensive.
The main benefit it provides, is the ability to guide a Fuzzer into difficult-to-reach branches.
Imagine the above IF statement. Asuming x is a 32-bit integer, there are 4.294.967.294 cases were we will go to the FALSE branch but only one input (namely 41) will lead to the TRUE path.
This is a typical roadblock for most Fuzzers, but with Symbolic Execution we can easily backtrack from the condition to the input and know what value to set, so that we reach into the difficult branch.
7. Value generation techniques – evolutionary
Remember when I rhetorically asked whether intelligent fuzzing has something to do with AI? People working on Fuzzers will usually reply “nothing!” This reply is about the same as Charles Darwin made to his contemporaries when asked whether he truly implied that we humans are apes. We do share some common ancestor with apes, yes, but that does not mean we are apes. In the same wake, evolutionary fuzzing does take some concepts, which are also widely used in AI applications. But that does not mean evolutionary Fuzzing is an AI application.
The introduction of evolutionary fuzzing (also called genetic fuzzing) by AFL in 2015 has been nothing short of a revolution for the world of automatic software testing, as discussed in my last post. It is very fast and can reach really, really deep into your code.
In short: evolutionary fuzzing really is the brightest candle on our cake right now and used throughout the fuzzing community.
So of course we will have an in depth look at it here.
Right, so how does it work?
Before we can answer this with regards to fuzzing, we first have to talk about evolutionary computation – its core concept.
Which is fascinating anyway, so ready yourself for an interesting dive into the rabbit hole.
Evolutionary computation
This concept origins back to the 1960s and was developed in three distinct variants before later being unified in the 1990s. It uses the core concepts of natural evolution to computationally solve a given global optimization problem.
Evolutionary computation uses three important components: the population, an evolution process and a fitness function.
- Population: We call the set of all known solutions the population. A singular solution is commonly referred to as a specimen. We typically start with a starting population of initial solutions and expand it by repeatedly applying the Evolution process and add new specimen to the population.
- Evolution: We call the process of creating new solutions evolution. During the evolution stage we pick one specimen and apply some transformations on it to create a new specimen. With a high probability we pick the specimen with the best fitness score. Rarely we pick another specimen at random (we do so to overcome local optima).
There are two common forms of transformations:- Mutations: random, usually minute, changes to parts of the specimen.
- Recombination: a second specimen is selected and parts of the two are combined to create a new one.
- Fitness function: The fitness of a specimen (in the classical evolutionary sense) is provided by applying the fitness function. This function is different for each optimization problem. Cost function is an alternative and commonly used name.
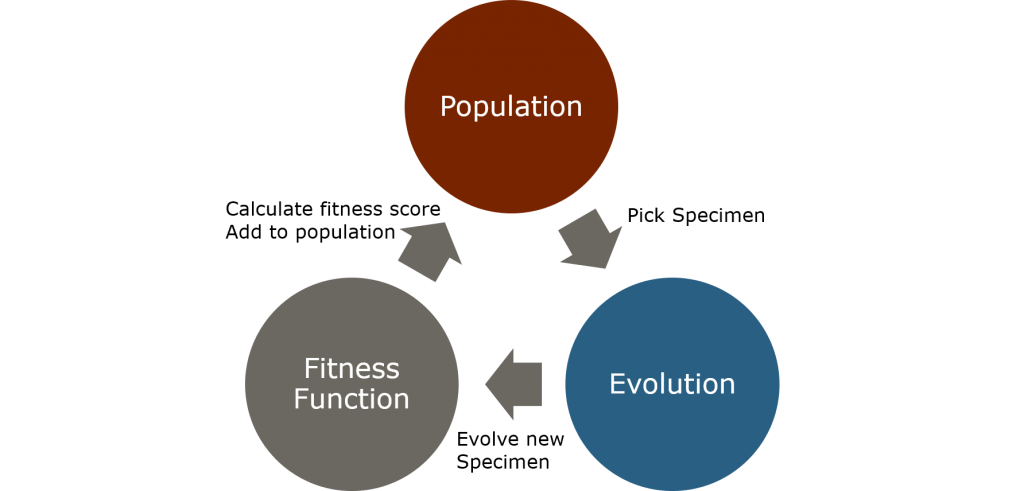
With those three components, it is pretty straight forward to create a heuristic algorithm to solve the optimization problem. You simply continue to create new specimen until a “good enough” solution is found. How to determine whether a solution is good enough depends on the problem. Often enough, evolutionary algorithms will accept a solution once a certain number of iterations did not provide a better solution or the fitness function reaches a sufficiently high (or low) value.
An evolutionary example
To better explain the concept, I will use a very simple example. Assume we have a line in the standard two-dimensional space. We want to find the point on the line which is closest to a given target point.
(And ignore the obvious mathematical solution for the sake of this explanation.)
- Population: We start with a random point on the line as our starting population.
- Evolution: As mutation we could for example randomly change one of the two coordination of a specimen point, or perform an increment or decrement on it. As for Recombination, we could take the x-coordinate from the first specimen and the y-coordinate from the second one. For the sake of demonstrating the concept, let us just assume that this would give us another point on the line – which obviously does not hold.
- Fitness Function: We will use the Euclidean distance between a specimen (point) and the target point. This means, the smaller the distance of a specimen, the closer it is to the optimal solution.
Evolutionary Fuzzing
Great… But what does this have to do with Fuzzing?
Well, remember the mutation-based approach right at the start?
Doesn’t this sound like we have half of an evolutionary algorithm right there?
Let us check it!
Population: we have an initial corpus, so: Yup.
Evolution: as the name implies, we have Mutation covered. Recombination is not always a concern of mutation based Fuzzers, so we might have to implement this. But that should be pretty straight forward, right? We’ll just do some split and merge operations at random positions and call it done.
Fitness Function: NullReference. Yeah, we have to look into that…
… later. We will just leave that as an open issue for now, okay? I will talk about this in greater detail in one of the next blog posts discussing code instrumentation.
For now let me just proclaim that it is indeed possible to collect data about which parts of a target’s source code is executed and in which order. That is we collect some kind of code coverage of our test executions. Which of course means that we can only do this in a white box case.
Regardless of these not-so-tiny details…
We can indeed use code coverage to create a fitness function for our Evolutionary Fuzzing!
It will preferably rank test cases which ‘covers’ more source code than others.
And to make it even better, we can have an additional condition: Specimen, which reach new areas of the target code, are preferred even further.
Why that additional condition?
Because “to go, where no test has gone before” is a noble thing! We do want our fuzzer to activate as much code as possible, to make sure it finds as many nasty little insects-in-hiding as possible.
Thus, test cases which reach new areas are good!
Fitness function remarks
I want to stress the fact that the above introduced fitness function is one possibility. It also happens to be the basic idea used in most modern Fuzzers such as AFL, libFuzzer, hongfuzz and many more beside.
But it is not the only possible solution.
We could also imagine a fitness function that does not use code coverage at all. Instead it would use feedback from a side-channel. Like response time or energy consumption.
We could have the fitness function prefer specimen which cause a longer response time or increased energy intake. This probably means the target had to do more computing and thus executed more code.
This may not be a better fitness function, but it has one big plus over the coverage based one: it works in a black box (or at least a grey box) situation, as it does not require source code access.
To wrap it up and look ahead
Whew, now that was a lot, right?
(I know, I typed all of this!)
But with this article, you should now have a pretty good idea how value generation of a certain Fuzzer actually works. And even more importantly, whether a certain Fuzzer will work for your target.
My recommendation when checking out a new Fuzzer is to just read over any mentions of dumb vs. intelligent as well as partially ignore the black vs white box discussion.
Both are too dependent on the authors’ respective definitions to be of much use.
Okay, now we know how to generate test values.
Great.
But how do we get them to the target?
This question may sound a bit easier than it actually is.
And that’s why we will take a look at it in my next post.



