Software is traditionally designed, coded, then tested. However, poor quality coding and a testing phase at the end of the process can add a significant amount of time and risk to a project. Delayed and extended testing has a knock-on effect. The longer bugs remain undiscovered, the more likely developers will work with poor quality software, causing more delays as more bugs are found. The ideal position is to have a process that supports testing as early as possible in the development life cycle and which enables changes to be made quickly.
Sounds like nirvana? It is possible!
Solving the problem of software quality and time to market is an ongoing fight, but Continuous integration (CI) helps developers and engineers to address these issues. CI pipelines focus on the ability to build and test an application every time a change has been made. There are five elements in the ultimate testing environment:
- Tools that allow developers to test whenever they need.
- Tools that provide visibility of testing completeness and auto generate test cases for incomplete code coverage.
- A repository that automates the job scheduling of the integration process.
- Parallelizing and scaling the test architecture to achieve fastest build time.
- Overlaying intelligence that understands the smallest number of retests required by a change to the source code.
The ultimate CI pipeline based on CI pipelines enables testing early and often in order to prevent ‘Integration Hell’. CI pipelines automate this process. The pipeline builds the code, runs the tests, and deploys the new versions of the SW.
Continuous integration is intended to be combined with automated testing. Historically, it was thought best to run all tests in the developer’s local environment and to confirm these tests were passed before committing code to the repository. As CI practices have developed, the concept of build servers has appeared to run tests automatically. This improves software quality, reduces time to market and builds a solid foundation for the code’s future.
Continuous integration: Who and what is Jenkins?
Without Jenkins – a server-based, open-source CI tool written in Java – it can take hours to perform an incremental build of an application and tests can take weeks to run. Jenkins enables continuous testing each time a source code change is made.
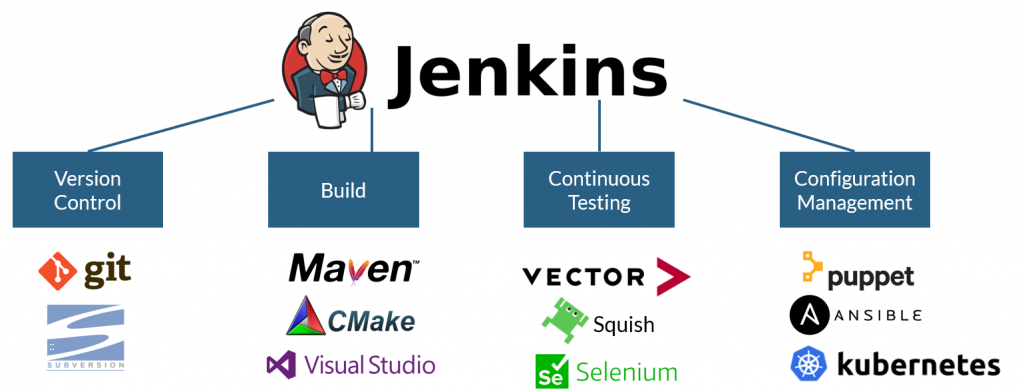
Introduced in early 2005, Jenkins (see Figure 2) has more than 400 plugins that allow it to be used with other coding languages to support the build and test of any project. Jenkins is a ‘job server’, with no bias as to which job needs to be performed.
It provides a distributed testing infrastructure that: allows a list of ‘nodes’ – physical or virtual machines – to be defined; ‘tags’ nodes to indicate the types of job that can be run; dispatches jobs to a list of nodes; and reports on job status when complete. Simply, Jenkins is a ‘butler’, taking instruction in the form of a list of jobs to be run.
While Jenkins plays a vital role in continuous integration, additional software is needed to manage the overall integration process and to complete a CI pipeline test environment. For CI pipelines to be most effective, all members of a software development team need to be able to share tests and be kept up to date with release readiness.
However, many current applications are deployed in multiple environments and configurations, so the build and test environment needs to cater to different operating systems and hardware combinations. This is usually controlled with configuration files, macros, and compiler options. Because it is critical that testing is completed for each configuration, the CI engine needs tools to manage the process.
Continuous integration pipeline: Adding parallelization
Organizing tests is one part of the CI process, but a parallel testing infrastructure is also crucial. When using Jenkins as the CI server, test targets need to be scrutinized and a popular choice is Docker, which can replicate the desired target environment. Using Jenkins and Docker, developers can select which environments to test and discover which cases need to be rebuilt and run, based on source code changes. Developers can set up different configurations of the same target environment to run comparable tests, allowing for complete code coverage testing. Docker makes testing more reliable, as having a model of the target environment –sometimes before it is available – means there is less chance of encountering errors with actual tests in the production environment. A complete continuous integration environment needs a platform to bring these elements together. The ideal solution will organize all test cases into groups that allow developers to map the application’s architecture and allow individual stacks to be tested and pushed forward for system tests.
Test what needs to be tested
With an environment that can carry out a complete suite of tests as quickly as possible, further improvement can be obtained by carrying out only those tests required to restore 100% completeness when a change is made to the source code. The well-known principle of change impact analysis is the final ingredient. State-of-the-art test automation tools have capabilities such as change-based testing. This is a feature that automatically identifies the minimum number of tests required to validate each code change. Using this capability, a test automation tool can be more efficient when used to revalidate code, as an example instead of running 10,000 tests, only a fraction of these may be needed following a change, significantly reducing the testing time from days to minutes.
Continuous integration example project
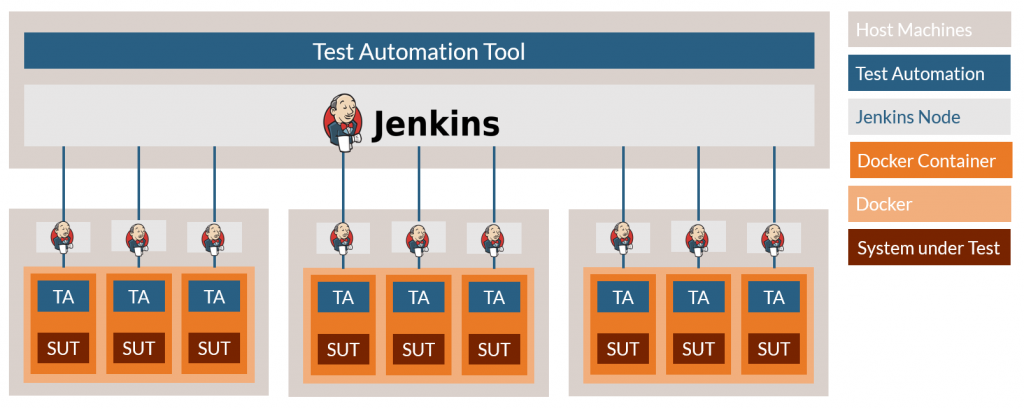
If our test automation tool has an example project of 20 environments with 122 tests. The test environment (see Figure 2) contains the test automation tool, a Jenkins server and nine slave nodes distributed over three slave servers using three Docker containers each. We know the baseline build and execution time is 47mins using one slave node and a Docker Container to run a complete set of tests.
To demonstrate the power of parallelism, 20 environment test jobs are created using the test automation tool we mentioned above, which pushes them into the Jenkins build queue. Jenkins pushes the first nine jobs to the slave nodes, where they execute in a Docker Container each. This continues until the full build and test are complete. The result is a fully distributed rebuild and test time of 7min 47s – six times faster.
If we change two modules and start a rebuild, the test automation tool and Jenkins determine the tests that need to be rerun, then push the jobs into the queue. The first module needs a complete rebuild and a test of the three test cases; the second module needs only an incremental rebuild, executing two of the nine cases. This requires only five of the 122 test cases to be rerun and an execution time for the rebuild of less than 2mins.
This demonstrates the power of a parallelized distributed testing environment that supports continuously changing requirements.